Aggregators Don’t Crash Cleanly — They Rot
What breaks differently when your service has to ask five friends before it can answer one question
Your service returned a 200 OK. Yet, three of the five downstream dependencies it called were actively struggling. Nobody got paged.
That is the exact failure mode that makes aggregators different. It is rarely a clean, loud crash. Instead, it’s a quiet degradation where your health dashboard looks green, your error rate looks fine, and your users are receiving a hollow shell of a response—missing prices, empty recommendations, and stale inventory.
Note: Baseline architectural principles still apply here. Everything discussed below is additive.
What is a Fan-Out Assembler?
A Fan-Out Assembler (or Aggregator) is a service whose job is to compose a response from sources it doesn't own. It calls the upstream services that do, assembles the results, and hands the payload back as if it came from a single source. The caller shouldn't know—or care—how many systems contributed behind the scenes.
This pattern shows up everywhere:
E-commerce: A product page API calling inventory, pricing, and recommendations in parallel.
Fintech: A checkout service calling fraud scoring, payment availability, and promotions.
AI Platform: An orchestration layer assembling multiple tool and LLM results into a single response.
The Structural Signature
The anatomy of a fan-out request always looks like this:
┌→ Inventory
Inbound request ──┼→ Pricing ────────→ Assembled response
├→ Recommendations
└→ Promotions
One inbound request. $N$ outbound calls. One assembled response.
That exact multiplication is what makes standard system concerns harder—and introduces entirely new failure modes.
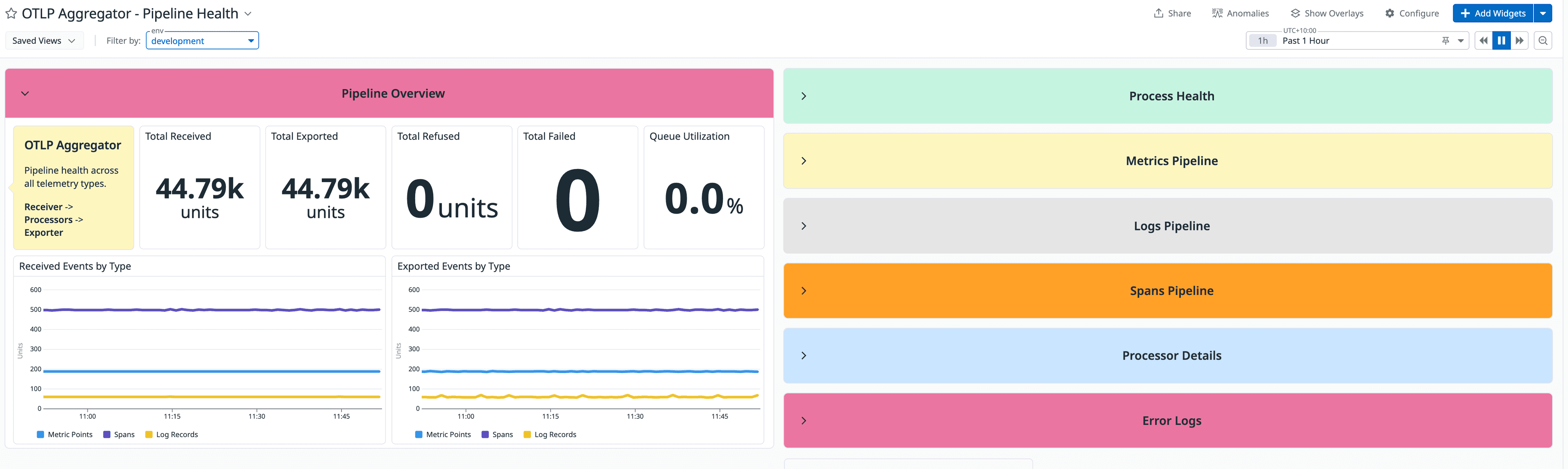
1. Observability: Stop Blending Your Signals
Your overall error rate sits at a comfortable 1.2%. Looks healthy, right?
Hidden deep inside that average, the pricing service is failing at 18% while everything else is clean. Your blended metric just buried a severe production issue.
You must tag every single metric per upstream—including latency histograms, error counters, and timeout rates. If you cannot answer "which upstream is degraded right now?" from a single dashboard view, your observability is lying to you by omission.
The Three Dashboard Layers Worth Building
| Layer | Focus | Metrics Included | Target Audience / Use Case |
|---|---|---|---|
| 1. Service Health | Blended signals | Overall throughput, average error rates | Initial Triage |
| 2. Dependency Deep-Dive | Per-upstream metrics | Per-service latency histograms, specific timeouts | Deep Diagnosis |
| 3. Business / SLI | Completeness rate | Percentage of partial vs. full responses | User Impact |
That third layer—the completeness SLI—is unique to assemblers and the most commonly missing. A response with empty recommendations isn't a 500 Internal Server Error, but it isn't healthy either. Without a completeness SLI, you have zero visibility into actual user experience.
2. Negotiate SLAs Before Writing Alert Thresholds
Your alert thresholds are meaningless without explicit agreements with each upstream team. Crucially, these agreements are not uniform.
The Pricing Team needs guaranteed delivery. Missing prices in a checkout flow is a Severity-1 incident, regardless of cause.
The Recommendations Team cares about responsiveness over completeness. A stale cache is perfectly fine; a slow response that degrades overall page load is unacceptable.
The Inventory Team has a staleness window. Data that is 5 seconds old is fine; data that is 5 minutes old means you are selling out-of-stock items.
For every single upstream, explicitly negotiate and document three core parameters:
1. Latency SLA ----------- Max acceptable response time? (Drives timeout configs)
2. Availability --------- Expected uptime? (Drives circuit breaker thresholds)
3. Acceptable Staleness -- How old is too old? (Drives cache TTL & fallback logic)
The Architectural Trade-off
This negotiation forces the completeness vs. freshness trade-off into the open. When an upstream is degraded, do you serve partial data (completeness takes the hit) or serve stale cache (freshness takes the hit)?
The right answer follows from what the upstream team agreed their data is for. If that agreement doesn't exist, your service will make the decision implicitly under pressure—which is the worst possible time to find out.
3. Resilience: These Patterns Only Work Together
Timeout, circuit breaker, bulkhead—you need all three. If you miss even one, the others cannot fully protect your system.
Timeouts alone: You keep hammering a struggling upstream, effectively becoming the attacker on a service desperately trying to recover.
Circuit breakers alone: Breakers trip on error rates, not pure latency. A slow upstream taking 8000ms may never trip the breaker, but it will exhaust your thread pool.
Both together, without bulkheads: One slow upstream still starves all the others. Shared connection pools mean one bad dependency takes down entirely unrelated requests.
The Solution: Complete Isolation
[Tight Timeouts] ──> Feeds failures into breaker fast ──> Upstream gets breathing room
[Bulkheads] ───────> Dedicates pools per upstream ───────> Keeps blast radius contained
Bulkheads are the most commonly skipped pattern. Dedicate separate connection pools per upstream. It is as much a diagnostic tool as a resilience one—when pools are isolated, a failure is immediately attributable.
💡 Don't forget Deadline Propagation: When your caller has already timed out upstream, stop execution. Burning I/O on a response nobody will ever receive steals capacity from live requests. Pass a deadline through the call chain (native in gRPC, or via an
X-Request-Deadlineheader) and verify it before making any outbound call.
4. Partial Failure Is a Contract, Not an Accident
When an upstream degrades, your service will make a decision. The question is whether that decision was made deliberately in a design meeting or emergently at 3:00 AM.
Every upstream must be explicitly classified:
Required Upstream: If degraded, fail the entire request. No partial response makes sense without this data. (Example: Payment availability in a checkout flow)
Optional Upstream: If degraded, fallback to partial data or a stale cache. The response remains meaningful. (Example: Product recommendations)
Document this classification, wire it into your fallback logic, and make the behavior observable. Log exactly which upstreams contributed to each response and whether any fell back. When a user reports missing data, you need to know in seconds whether it was an intended fallback or a native bug.
5. Operations: Reducing Blast Radius
Runtime Kill-Switches
This is the most operationally vital pattern in this post, yet the most commonly absent.
Without a kill-switch: Detect ➔ Diagnose ➔ Write PR ➔ Wait for CI/CD deploy ➔ 10+ minutes of downtime.
With a kill-switch: Detect ➔ Diagnose ➔ Toggle Feature Flag ➔ Contained in under 60 seconds.
Whether you use LaunchDarkly, Unleash, AWS AppConfig, or a polled Parameter Store value—implementation matters less than existence.
Scale on I/O Signals, Not CPU
Assemblers are fundamentally I/O-bound. Your CPU will sit idle while threads block waiting on slow upstreams. Scale your infrastructure based on queue depth, pool saturation, or latency percentiles. If you inherited a default CPU-based autoscaling config, change it.
Model Your End-to-End Timeout Arithmetic
Your total end-to-end timeout must be logically less than your upstream call sequence. If you are calling three upstreams in parallel with 500ms timeouts, your assembler's overall timeout needs to account for that parallel execution plus internal processing overhead—do not just guess a number.
The Assembler Readiness Checklist
🟢 Phase 1: Go-Live Gates (All must be YES)
[ ] Are metrics tagged per upstream rather than blended?
[ ] Is there a completeness SLI tracking partial responses?
[ ] Have latency, availability, and staleness SLAs been agreed upon with each upstream team?
[ ] Is every upstream explicitly classified as either Required or Optional?
[ ] Is fallback behavior explicitly defined and observable for every upstream?
[ ] Does every upstream have a dedicated connection pool (bulkhead)?
[ ] Does every external call have a tight, explicitly bounded timeout?
[ ] Is deadline propagation implemented across the execution chain?
🔵 Phase 2: Operational Excellence
[ ] Is there a runtime kill-switch per upstream, operable without a deployment?
[ ] Is autoscaling driven by I/O saturation or latency instead of CPU usage?
[ ] Has chaos testing (fault injection) been run per upstream to verify fallbacks trigger automatically?
[ ] Has the end-to-end timeout math been modeled explicitly against upstream parallel call arithmetic?
Summary
You are not just building a service that happens to call multiple upstreams. You are building a fault isolation layer.
When designed correctly, your callers will always know exactly what they got, how complete it was, and how fresh it was. That transparency is your architectural contract—everything else is just the infrastructure keeping it alive.